Follow up article to this one here
So recently I read this article about how the Bitcoin community had executed
what’s known as a “Zero-Knowledge Contingent Payment”; a pretty neat concept.
What was really interesting for me was the (simplified) underlying algorithm for generic
zero knowledge proofs. It took me a while (and some questions asked to helpful folks on the
Internet) to understand it fully, but the concept is quite intriguing and sounds rather magical. I
thought I’d explain it here in an accessible way, both so that others can get it and to
improve my own understanding.
I intend this article to be read by people with a programming or mathematical background,
who have some understanding of what logic gates are. Please let me know if you feel that something
is inadequately (or wrongly) explained.
So what is a zero knowledge proof?
Let’s say Alice has a problem she wants to solve. It could be a mathematical problem, like
factorizing a large number, or coloring a map (or graph!) with only three colors, or solving a
Sudoku puzzle. Anything where you can write a program to verify the solution.
She doesn’t have the resources to solve the problem herself, but wants to buy a solution from
someone else. She makes the problem public, and Bob says he has a solution.
However, Alice is skeptical. She’s not sure if Bob is telling the truth here, and would like some
evidence that he does indeed have a solution. At the same time, Bob is not willing to share his
solution with Alice without getting paid. They also don’t want to involve a third party; let’s say
this is a rather Important Sudoku Puzzle that affects National Security ¯\_(ツ)_/¯.
What Alice and Bob need here is a way for Bob to prove to Alice that he has the solution, without
sharing the solution, and without involving a third party.
It turns out that this is totally possible (magical, right!). There’s a quick example
on Wikipedia of a simple proof of a non-mathematical fact – whether or not someone
has a key to a particular door.
For proving more complicated problems, we have to digress into some basic crypto first
Interlude: Hashes and commitments
Feel free to skip this if you know what a hash function and a nonce is.
In cryptography, there’s something called a “hash function”. In essence it’s an “irreversible”
function whose output is known as a “hash”, with the following three properties:
- It’s not computationally intensive to calculate the hash of an input
- Given a hash, it’s a computationally hard problem to calculate an input to the hash function that results in this hash, usually involving brute force
- It’s also a computationally hard problem, given an input and a hash, to find a different input (especially a different input that is similar to the first one) that produces the same hash.
Note that multiple values may result in the same hash.
The result of this is basically that hashes are hard to forge. If Bob shares a hash Y = H(X) with
Alice, where X is some secret data and H is a hash function, if Bob reveals X at some later
point, by checking that Y = H(X), Alice can be reasonably certain that the value shared by Bob was
indeed the original input to the hash function and not tampered with in a way that the same hash was
produced. Similarly, Bob can be certain that knowing only Y, Alice cannot reverse-engineer X
since the hash function is “irreversible”.
This brings us to the concept of a commitment. Hashes can be used as described above to “commit” to
a value. If Bob decides on a number X, and makes its hash Y public, he has committed to this
value without revealing it. When he does decide to reveal it, he is forced to reveal X and not
some modified bogus value, thus making the “commitment” binding.
Some of you may have noticed a flaw here: It’s hard to commit to small numbers, or things that come
from a restricted set. If Bob wishes to commit to the number 5 (without revealing it), or the
color red (out of a set of three colors), Alice can just try H(0) to H(9) or H(red),
H(green), H(blue) and find out which one matches. After all, hashes aren’t supposed to be resilient
to brute force attacks, and brute force attacks become very easy when the set of inputs is tiny.
A solution to this is to use a nonce (also known as a “trapdoor”). Bob commits to 5 by hashing
the string 5-vektvzkjyfdqtnwry, where vektvzkjyfdqtnwry is a random value he selected, known as
a “nonce”. When Bob wishes to reveal the value, he just reveals 5-vektvzkjyfdqtnwry and Alice is
convinced that the original value committed to was indeed 5. Of course, this requires some agreement
on the format of the nonce; in this case the nonce is just “everything after the dash”. Note that
the nonce is private, and only revealed when Bob wishes to reveal the committed number.
Note that each new commitment should use a new nonce. Otherwise, information can be leaked; for
example if Bob needs to commit to three numbers (say, 2, 5, 2) in a way that they can be
individually revealed, he shouldn’t compute the hashes for
2-vektvzkjyfdqtnwry, 5-vektvzkjyfdqtnwry, 2-vektvzkjyfdqtnwry, since the first
and last hashes will be equal and Alice will know that the committed values behind them are probably
the same too (something which you may not wish to reveal).
Another issue that can turn up is a “rainbow table”, where one party comes into the game with a
precomputed table of hashes of all strings up till a certain number of characters. One solution for
this is to increase the nonce size, however since Bob decides the nonces it’s possible for him to
smartly select them if he’s the one with a table. The solution here is to use a “salt”, which is a
large random string combined with the committed value and hash. Bob and Alice could, for example,
mutually decide on a salt of asdcjyxeafxjvikfzmnyfqsehsxwxsfywbreb, and when Bob wishes to
commit to the number 5, he hashes
asdcjyxeafxjvikfzmnyfqsehsxwxsfywbreb-5-vektvzkjyfdqtnwry. Note that salts work similar
to nonces here, however the salt is known publically (you can model it as a last-minute modification
of the agreed-upon hash function H, since H'(X) = H(add_salt(X))). In some cases, you may also
want a per-instance salt, which is mutually decided every time Bob wants to compute a hash.
Hashes are a useful building block for many things; they’re a key component in password security, as
well as being part of all kinds of cryptographics protocols. In this post we’ll mainly focus on
their ability to be used as a unbreakable commitment.
Back to your regularly scheduled blog post.
Coloring graphs
The classic example of zero knowledge proofs is graph coloring. I’ll run through a quick
explanation, though it’s explained beautifully here too.
Let’s say Alice has a graph:
No, not that kind, Alice. The other graph.
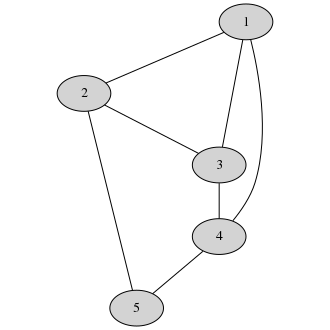
She wants it colored such that no two adjacent nodes share a color. This is an NP-complete problem (so
it can take up a lot of computational resources to solve). Of course, this graph is small and easy
to color, but that’s just for the sake of this blog post.
Bob, using his trusty Crayola™ 3-crayon set, has managed to come up with a valid coloring:
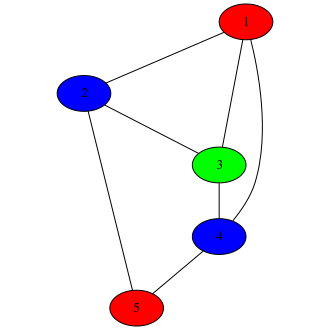
He wishes to prove that he has this to Alice, without revealing it or involving a third party.
Probably for National Security Reasons. Something something Nicolas Cage.
Bob and Alice meet, and Alice gives him a large piece of paper with the (uncolored) graph drawn on
it.
Bob goes into a private room, and colors it. He also covers each graph node with a hat. Alice now
enters the room.
Alice chooses an adjacent pair of nodes. Let’s say she chooses 1 and 2. Bob removes those two hats
(since Alice is watching him, he has no chance to tamper with the colorings underneath the hats
before revealing them). Now, Alice knows the colors of nodes 1 and 2:
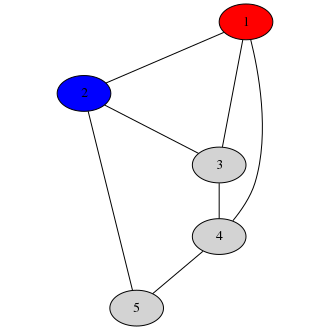
This lets her verify that nodes 1 and 2 had different colorings in the graph Bob drew.
Note that this doesn’t actually tell her anything about Bob’s coloring aside from the increased
probability of correctness. The colors can always be permuted, so any valid coloring would give
the same answer here if the colors were permuted so that 1 is red and 2 is blue. This is important;
we don’t want to leak information about Bob’s solution aside from the fact that it is correct.
Nor is this information enough to verify correctness. Bob could have equally drawn a wrong
coloring.
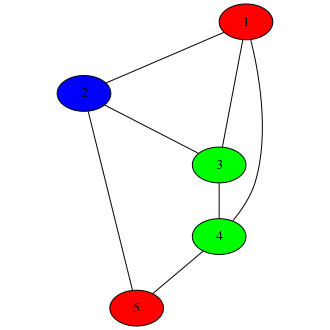
(clearly someone wasn’t paying attention in kindergarten)
Since Alice only looked at nodes 1 and 2, she didn’t see anything wrong with the graph. But if she
had by chance picked nodes 3 and 4, Bob’s deception would have been revealed.
So she only has 14% (1/7) certainity that Bob’s graph is correct.
However, we can run this experiment again. Bob can permute the colors, draw on a fresh copy of the
graph, and ask Alice to choose another pair of adjacent nodes. She can check this, and the
probability of correctness will increase to around 27% (1 - (6/7)*(6/7)).
Since Bob has permuted the colors, Alice cannot use the information from the previous round to glean
any information about Bob’s solution in this round. Of course, Bob is free to produce a completely
different coloring (one that is not a permutation), with a different flaw this time. Regardless of
where the flaw is, Alice still has a chance of uncovering it each time.
This can continue until Alice is satisfied that there is a very little chance that Bob has cheated.
For example, after 60 rounds, Alice would be 99.99% certain.
Note that this didn’t actually involve any cryptography; it was an algorithm based on information
flow. However, if you want this to work securely (in the current solution Alice could push Bob away
and reveal all the nodes herself) and make it work without requiring Alice and Bob to be in the same
location, you need to use hashes.
Remember when Bob colored the graph whilst alone in the secret room? Once Alice had entered the
room, this coloring was committed. There was no way for Bob to tamper with this coloring.
We do the same thing here. After obtaining a valid coloring, Bob commits to this coloring by
calculating some hashes.
| Node | Color(private) | Nonce(private) | Hash |
|---|
| 1 | red | wmdqatobck | e1f957bedcceeb217305bfa12cbee4abac36eff1 |
| 2 | blue | fmcbpzkgyp | 87d9d7239909c28ec8d73a3b9a99673cbf870046 |
| 3 | green | dktuqvrsss | a40bafb81149937c77ae55589aff1b53d9c043d8 |
| 4 | blue | auhbyuzkmz | b3503962937850f7c1b59cf4b827ca40a62b122a |
| 5 | red | gfunjcmygk | d8db52bb36ca595b9231180c1055fe3958c3ea7d |
(The hashes here are calculated using SHA-1 for the hashing algorithm. It’s not considered very
secure anymore, but the secure ones all output huge hashes which spill over the page)
Bob sends the public part of the table (the node-hash mapping) to Alice. Alice asks for nodes 1 and
2, and Bob reveals the entire table entry for those two nodes (including the nonce).
Note that since Alice now knows the color and nonce for nodes 1 and 2, she can verify that the
colors shown are indeed the ones Bob committed to. echo red-wmdqatobck | sha1sum if you want to
check on a local Unixy shell.
As in the previous case, Alice can repeat this algorithm until she reaches an acceptable level of
certainty (each time with a permutation of colors and a new set of nonces).
A lot of zero knowledge proofs (but not all!) are inherently probabalistic and interactive. They
involve multiple rounds where in each round the prover (Bob) commits to something, the verifier
(Alice) challenges the prover to reveal some information. The process repeats, with the certainity
on the verifier’s side approaching 100% as more and more rounds happen.
Zero Knowledge Proof for General Execution
It turns out that you can have a ZKP exchange for the execution of any algorithm that can be
transcribed into combinatorical logic. In other words, you should be able to write the program
without loops and recursion, though loops bounded by a constant are allowed. This isn’t as
restrictive as it seems, usually verification is a straightforward task not involving convoluted
loops. The examples above (graph coloring, sudoku, prime factorization) can all be verified
without loops.
The algorithm shown here is by Gregory Maxwell, originally published here. It’s somewhat
inefficient, but it demonstrates the idea behind ZKP for general execution. As mentioned there, it
can be optimized using techniques described in this paper.
Let’s get started. Any combinatorical program can be decomposed into a bunch of AND and NOT
gates, taking in a bunch of input values and giving out one or more output values. For simplicity
let’s assume that the problem statement (i.e. the specific sudoku puzzle, etc) that needs verifying
is embedded inside the program, and the final output of the program is just a single boolean
indicating whether or not the input is a solution. This algorithm, however, can work for programs
with arbitrarily large outputs.
Alice and Bob do this decomposition. The also agree on a numbering of the AND gates. Let’s say
that there are N AND gates. We’re mostly going to ignore the NOT gates for the purpose of this
article – they’re there, but they aren’t modified or anything.
Creating encrypted AND gates
Now, Bob creates 4*N encrypted AND gates. This is an AND gate, but with the
inputs and outputs all muddled up.
This is a regular AND gate:
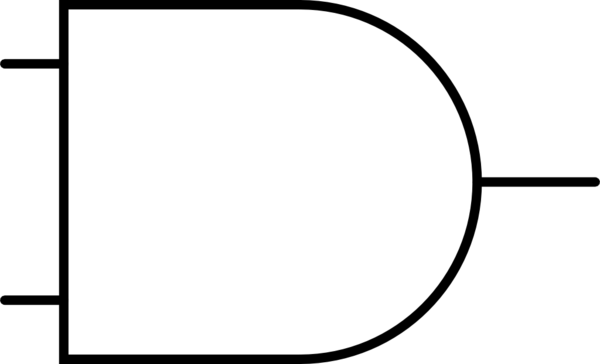
This is an encrypted AND gate:
(yes, it can be identical to an AND gate)
So is this:
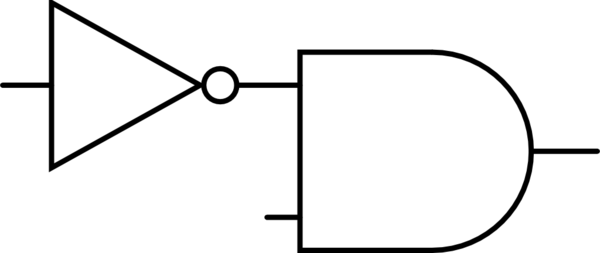
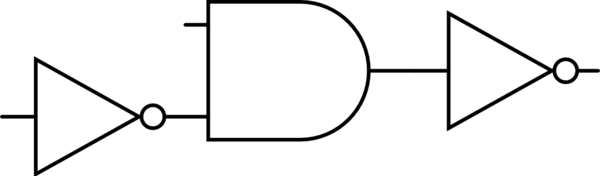
and this:
Basically, each input and the output may or may not be inverted. We can model this in a different
way, there is an encryption key corresponding to each input and output. This key is XORd with the
input/output (so if the key is 1, the wire is inverted, and if the key is 0, the wire is not
inverted).
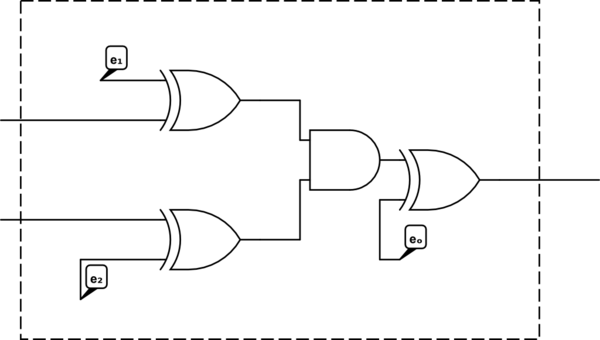
A regular AND gate has a truth table as follows:
| Input 1 |
Input 2 |
Output |
| 0 |
0 |
0 |
| 1 |
0 |
0 |
| 0 |
1 |
0 |
| 1 |
1 |
1 |
This truth table, encrypted (with the input keys \(e_1 = 1, e_2 = 0\) and output key \(e_o = 1\))
is:
| Encrypted Input 1 |
Encrypted Input 2 |
Encrypted Output |
| 1 |
0 |
1 |
| 0 |
0 |
1 |
| 1 |
1 |
1 |
| 0 |
1 |
0 |
So, if the encrypted gate gets the (encrypted) inputs 1 and 0, its (encrypted) output will be 1.
Since XOR is its own inverse (\(x \oplus y \oplus y\) is just \(x\)), if we wish to encrypt
an input before piping it through this gate, we just XOR it with the relevant input key. If we wish
to decrypt the output, we again XOR it with the output key. The XOR gates being applied will just
cancel out with the internal encryption gates. In other words, encryption and decryption are done
with the same operation!
To recap, the dotted box below is an encrypted AND gate. An encrypted input enters from the left,
and is decrypted by the internal XOR gate to obtain the actual input, which is piped through the AND
gate. To encrypt an input so that it can be passed into this gate, one uses the same key with an XOR
(not shown in the diagram). Similarly, the actual output of the AND gate exits on the right, and is
encrypted by the XOR gate at the output to get the “encrypted output” (the wire that extends out of
the box). To decrypt this, one must apply the same XOR operation to the encrypted output to recover
the actual output of the gate.
Creating adaptation keys and commitments
Now, unlike regular AND gates, these encrypted AND gates cannot be composed. The output of an
encrypted AND gate is encrypted, with a potentially different encryption key as to that of the next
gate’s input. So, we insert an “adaptation key” between the two. For example, if the output of the
first gate is connected to the first input of the second gate, we need to insert this operation
between the two gates:
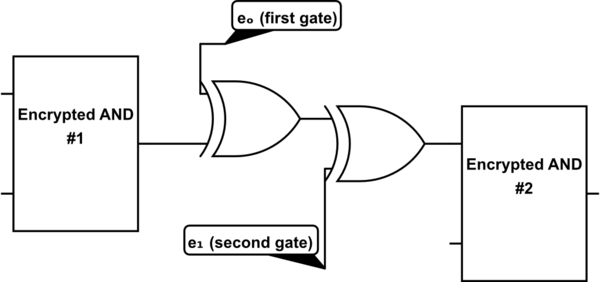
We XOR by \(e_o\) of the first gate (to decrypt), and then again XOR by \(e_1\) of the second gate (to
reencrypt). This operation is the same as XORing by \(e_o \oplus e_1\), which is the
“adaptation key”. Every pair of encrypted gates will have an adaptation key for every configuration
they can be placed in.
Alright. Bob creates a ton of these “encrypted gates”, and calculates all the adaptation keys for every possible pair of gates. He also mixes up the truth tables of each encrypted gate.
Now, he commits to these truth tables. A commitment for each entry in each truth table is made, so
he’ll end up with something like this:
| Encrypted Input 1 |
Encrypted Input 2 |
Encrypted Output |
nonce |
commitment |
| 0 |
0 |
1 |
.. |
H(001 + nonce) |
| 1 |
0 |
1 |
.. |
H(101 + nonce) |
| 0 |
1 |
0 |
.. |
H(010 + nonce) |
| 1 |
1 |
1 |
.. |
H(111 + nonce) |
He also commits to each of the adaptation keys and each of the encryption keys.
As usual, all the commitments will be sent to Alice. Alice will then have data like: “Commitment for
Gate 1 entry 1: .., Commitment for Gate 2 entry 2:.., … Commitment for Gate 2 entry 1: .., ….
Commitment for adaptation key between Gate 1’s output and Gate 2’s first input: .., Commitment for
adaptation key between Gate 1’s output and Gate 2’s second input: .., Commitment for encryption key
for Gate 1’s first input, …”.
Shuffling and revealing
These commitments are taken in some predefined order, and the resultant monster string is hashed
(without a nonce). This “superhash” is used as the seed to a pseudorandom number generator which is
used to shuffle the gates. Both Alice and Bob can calculate this shuffling.
This post-shuffle ordering is used after this point. The hash-shuffle is important here because it
adds a layer of tamper protection. If Bob wishes to tamper with the, say 4th gate post-shuffle, Bob
would have to create a bad gate before making the commitments; this changes the commitments, and
thus the shuffle order, and so the tampered gate will not end up being the 4th gate. Basically, it’s
hard to control where the tampered gate will end up.
Now, out of the 4N gates, Bob takes the last 2N, and reveals everything about them: Their
encryption keys, the nonces for their truth table commitments, and all adaptation keys between
these gates (along with the nonces for the adaptation key commitments).
Alice ensures that everything in this revealed data adds up. All the truth tables, after decryption,
should actually be AND gate truth tables. All adaptation keys must match up with their relevant
encryption keys. All commitments must match up.
Double trouble!
Bob duplicates the AND-and-NOT-gate based circuit. He now has two identical circuits which take
the same inputs, and have one output each. In itself this is pretty useless; this circuit is
obviously redundant. However, in the context of encrypted gates, this redundancy becomes useful.
Bob drops in the 2*N encrypted gates into this double-circuit, using the post-shuffle ordering of
encrypted gates and the predecided numbering of the AND gates in the circuit. He puts the
necessary adaptation gates (i.e. an XOR operation with the relevant adaptation key) between
encrypted AND gates to make the circuit work. Note that each “half” of the circuit has a different
set of encrypted gates, and thus a different encryption key for each input. There are NOT gates here
too (from the original circuit, which was made of ANDs and NOTs); they stay in place (the adaptation
gate can go on either side of them) with no modifications or encryption.
Execution
Let’s recall that Bob is claiming to have the correct input for the original circuit – the input
that makes that circuit output true.
Since Bob has all the encryption keys, he can encrypt this correct input to get the correct
encrypted input, which should make the new circuit output true (well, encrypted true) as well.
Bob goes ahead and does this. He encrypts the input (since there are different encryption keys for
either side of the circuit, he does this twice), and runs it through the circuit. He notes down the
truth table entry utilized for each gate. He ensures that the output, once decrypted, is true (it
should be, if everything has been done correctly till now).
Verification
He now reveals the details of the program execution to Alice. He reveals:
- All adaptation gates involved (and their nonces, to verify the commitments)
- All truth table entries involved in the execution (and their nonces …).
- The output encryption key (and its nonce)
- The encrypted inputs
Alice goes ahead and verifies that the commitments have not been reneged upon. Note that she also
now has a full execution history. It’s an encrypted history – she can’t calculate the original
input from it – but she can verify that the execution was faithfully carried out. While she doesn’t
have the entire truth table for any encrypted gate, she has the entry that was used in the
execution, which is enough. She just has to ensure that the inputs to a gate match the truth table
entry, use the entry to see what the output is, apply the relevant adaptation key to get the input
for the next gate, and repeat.
And there you have it. Alice has verified that Bob faithfully executed her verification circuit, and
thus he must have the correct answer to her problem.
Tampering?
Let’s see if it’s possible for Bob to tamper with any of this. If Bob wishes to tamper with one of
the gates, he has to tamper with the gates before calculating commitments, which means that the
shuffling will get mixed up, which will mean that he can’t control where the tampered gate will end
up in the final circuit. This is compounded by the fact that half the gates are revealed (so the
tampered gate may end up in the wrong set), and that there are two copies of the circuit (so you
need to tamper with both sides simultaneously, requiring even more luck on getting the shuffle where
you want it).
The probability of Bob being able to execute a succesful tamper can be adjusted by increasing the
number of revealed gates, and increasing the duplication of the circuit. There is also the
aforementioned fudge factor that can be introduced by having Alice choose where each encrypted gate
should go after Bob has already provided commitments, and finally the procedure can be repeated as
many times as necessary with a fresh set of encrypted gates to increase certainty. Unlike the graph
coloring algorithm (where the uncertainty in a single run was large – if Bob has a couple of wrong
edges there’s relatively small chance he’ll get caught); here in a single run it is Bob who has a
massive disadvantage, since he must tamper with exactly the right gates, and there’s very little
chance that his tampered gates will fall in the right place based on Alice’s chosen ordering.
Additionally, tampering with the gates in the first place is hard, since you need to avoid having
them get revealed. I think that with reasonable (e.g., not asking for something like 1000 duplicated
circuits) choices on the level of duplication and number of revealed gates, it’s possible for Alice
to get a very high level of certainty without needing to conduct multiple rounds.
How about the opposite question: Can Alice find out anything about the input, aside from the fact
that it is correct, from the information she has? At first glance it seems like she can, because she
can see the whole path of execution. In case of a program with non-constant loops, this would be
damning, since she can figure out how many executions happened (and thus know the decrypted value
for the number of loop iterations) and backtrack using that in a cleverly-written program. However,
this program has no loops.
Looking at it closely, any encrypted history of execution can be changed to a different encrypted
history of execution for the same nonencrypted execution by adding NOT gates wherever they don’t
match, and then absorbing these NOT gates into the input or output keys (by NOTing them) of the
adjacent encrypted AND gates. This means that without knowing the details of the encrypted gates,
all histories of execution are equally possible for a given actual execution. Therefore,
knowing only a history of execution does not provide you further information about the actual
execution, since it could equally have been for some other history of execution.
Bonus: Fixing the escrow and Bitcoin
(I’m going to assume basic knowledge of Bitcoin later on in this section)
After all this, we still only have a way of Bob proving he has a solution. There’s no way of
securely exchanging the solution for money (or whatever) without involving a trusted third party to
handle the swap. This is known as escrow, where a third party is given both items for swapping;
and after checking that everything is in order the third party completes the swap.
We can build on this so that the third party is only trusted with the money, and cannot actually
peek at the answer.
It’s pretty straightforward: Bob and Alice mutually agree on a shared secret “pad” P. Bob takes his
answer, bitwise-XORs it with the pad (which is of the same length as the answer) to get padded input
X, and then hashes it to get hash Y.
Now, initially we had a verification program which proves the statement “This input is a solution to
Alice’s problem”. We modify this program so that it proves the following two statements:
- This input is a solution to Alice’s problem
- When the input is XORd with P, and subsequently hashed, the hash that comes out is Y
Alice and Bob now go through the ZKP algorithm and the above is proven. Of course, they must keep
the exchange between themselves, since the value of the pad (which can be extracted from the
circuit) must remain secret.
Assuming that Bob isn’t able to cause any hash collisions, Alice at this point would be happy with a
number that, when hashed, gives Y. This is something that escrow can verify, since neither Y nor X
can be reverse-engineered to get the original answer unless you have P.
Now, Alice puts the money in escrow, and notifies the third party handing escrow of the value of Y
(the hash). Bob puts the padded input X in escrow as well. The third party verifies that Y is the
hash of X, and releases the money to Bob and the padded input to Alice. Since Alice knows pad P, she
can XOR it with X to recover the original real input. Everyone walks away happy!
Well, maybe not. There still is the danger of the third party handling escrow to walk away with the
money. Why trust any one party?
Turns out that Bitcoin proves to be an alternative to this situation. The technique described in
Greg Maxwell’s article (called Zero-Knowledge Contingent Payment), builds upon
the above protocol using “scripts” in Bitcoin.
The way a Bitcoin transaction works is that anyone (well, the first person) who can solve the
embedded challenge is allowed to use the money contained in it. Like a piñata. Except with money
instead of candy and public-key cryptography instead of a stick.
Most Bitcoin transactions pay directly to a person, and they use a standard kind of challenge (the
actual script is here). If Alice wishes to pay Bob 5 BTC, Alice crafts a
transaction which says “anyone with the private key behind Bob’s public key (his address) may spend
this money”. Of course, in practice this means that only Bob can spend the money. Alice created a
piñata which only Bob can break.
We can build on this to make the Bitcoin network behave as a trustworthy escrow. After having
stepped through the zero-knowledge protocol and being confident that Y is the hash of the padded
input, Alice crafts a transaction which says “anyone with a string that results in this hash may
spend this money”. Bob has this string; it is the padded answer X. He makes a transaction with
X as part of the input script (so that he can claim the money); and the Bitcoin network accepts it.
Assuming Alice and Bob are not able to tamper with each others’ local networks, by the time Alice
sees the transaction containing X, the network should have accepted this transaction already (though
it may not yet be part of the blockchain), and Bob should be getting his money.
(In case the crucial part is trusting that the escrow doesn’t run off with the money, and you don’t
care if other people can see the answer, you can skip the padding step and directly hash the input.
I believe the proof of concept executed in Greg’s post did this, but I’m not sure)
Thanks to Shantanu Thakoor, eternaleye, and ebfull for feedback on drafts of this post